


کامپایلرها

فهرست مطالب
آخرین به روزرسانی در 17/03/2022
در این مقاله قصد داریم در رابطه با کامپایلرها و طراحی کامپایلر بپردازیم .
در ابتدای مقاله به معرفی مفاهیمی در رابطه با کامپایلرها خواهیم پرداخت و پس
از آن به بررسی کاربرد ، مزایا و انواع آن ها می پردازیم .
به طور کلی در این آموزش قصد ارائه ی مفاهیم کاربردی و در حد آشنایی را داریم .
تا پایان این مقاله ما را همراهی کنید .
کامپایلر چیست ؟

به طور کلی کامپایلر نرم افزاری است که یک برنامه نوشته شده به زبان سطح بالا (زبان منبع) را
به زبان سطح پایین (ابجکت/هدف/زبان ماشین) تبدیل می کند.
کامپایلر سورس به سورس یا ترانس کامپایلر یا ترانسپایلر ، کامپایلری است که کد منبع نوشته شده
در یک زبان برنامه نویسی را به کد منبع زبان برنامه نویسی دیگر ترجمه می کند.
تعریف اصطلاحات کاربردی
زبان سطح بالا (High-Level Language) :
اگر برنامه ای حاوی دستورات #define یا #include باشد، HLL نامیده می شود.
این زبان ها برای ما ساده و قابل درک اما برای ماشین ها سخت می باشد .
این تگ های (#) دستورالعمل های پیش پردازنده نامیده می شوند.
آنها پیش پردازنده را راهنمایی می کنند که چه کاری انجام دهد.
پیش پردازنده (Pre-Processor) :
پیش پردازشگر همه دستورات #include را به وسیله ی فایلهایی به نام inclusion
و همه دستورالعملهای #define با استفاده از بسط macro حذف میکند.
زبان اسمبلی (Assembly Language) :
نه به صورت باینری است و نه زبان سطح بالایی دارد.
این یک حالت میانی است که ترکیبی از دستورالعمل های ماشین و برخی دیگر از داده های مفید مورد نیاز برای اجرا است.
اسمبلر (Assembler) :
برای هر پلتفرم (سخت افزار + سیستم عامل) یک اسمبلر خواهیم داشت.
آنها به صورت گلوبال نیستند زیرا برای هر پلتفرم به صورت مجزا یک نوع اسمبلر استفاده می شود .
خروجی اسمبلر یک فایل شی نامیده می شود که زبان اسمبلی را به کد ماشین ترجمه می کند.
مترجم (Interpreter) :
یک مترجم زبان سطح بالا را به زبان ماشین سطح پایین تبدیل می کند، درست مانند یک کامپایلر.
اما آنها در نحوه خواندن ورودی متفاوت هستند.
کامپایلر در یک حرکت ورودی ها را می خواند، پردازش را انجام می دهد و کد منبع را اجرا می کند
در حالی که مترجم همان عملیات را به صورت خط به خط انجام می دهد.
کامپایلر کل برنامه را اسکن می کند و آن را به کد ماشین ترجمه می کند در حالی که یک مترجم
برنامه را به شکل یک دستور ترجمه می کند.
لازم به ذکر است برنامه های مترجم شده معمولاً نسبت به برنامه های کامپایل شده کندتر هستند.
Loader/Linker :
کد پویا را به کد ثابت تبدیل می کند و سعی می کند برنامه را اجرا کند که منجر به یک برنامه در حال اجرا یا یک پیام خطا می شود (یا گاهی اوقات ممکن است هر دو اتفاق بیفتند).
لینکر انواع فایل های شی را در یک فایل بارگذاری می کند تا آن را قابل اجرا کند.
سپس لودر آن را در حافظه بارگذاری کرده و اجرا می کند.
مراحل کار کامپایلر
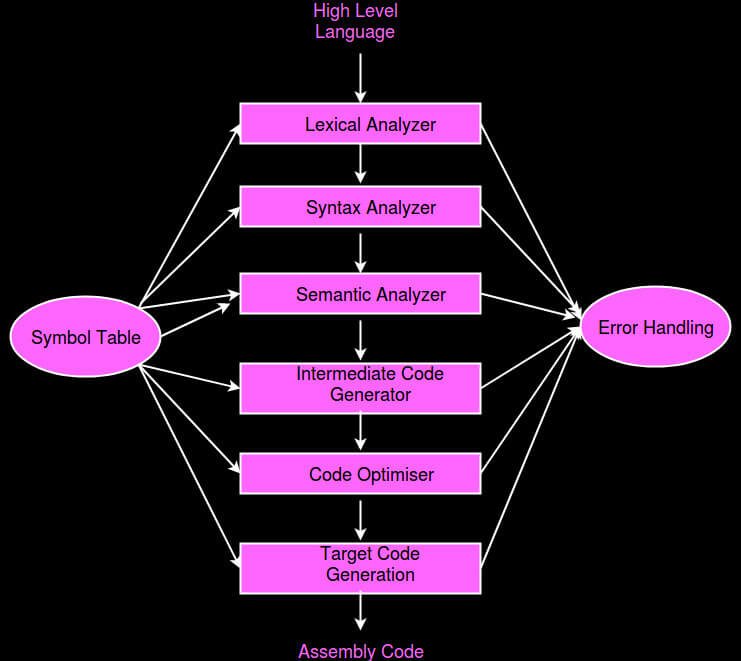
مرحله تجزیه و تحلیل :
در این مرحله یک نمایش میانی از کد منبع داده شده ایجاد می شود که عبارتند از :
1-Lexical Analyzer
به آن اسکنر نیز می گویند. خروجی پیش پردازنده (که گنجاندن فایل و گسترش ماکرو را انجام می دهد) را به عنوان ورودی می گیرد
که در یک زبان سطح بالا خالص است. کاراکترها را از برنامه منبع می خواند و آنها را به واژگان
گروه بندی می کند.
هر واژگان مربوط به یک نشانه است. نشانه ها با عبارات منظمی که توسط تحلیلگر واژگانی درک می شوند، تعریف می شوند.
همچنین خطاهای واژگانی (مانند نویسه های اشتباه)، نظرات و فضای خالی را حذف می کند.
2-Syntax Analyzer
قوانین برنامه نویسی را می توان به طور کامل در چند خروجی نشان داد.
با استفاده از این خروجی ها میتوانیم ماهیت برنامه را نشان بدهیم .
ورودی باید بررسی شود که آیا در فرمت مورد نظر است یا خیر.
درخت تجزیه را درخت مشتق نیز می نامند. درختان تجزیه عموماً برای بررسی ابهام در دستور زبان داده شده ساخته می شوند.
قوانین خاصی در ارتباط با درخت اشتقاق وجود دارد.
- هر شناسه یک عبارت است.
- هر عددی را می توان یک عبارت نامید.
- انجام هر گونه عملیات در عبارت داده شده همیشه منجر به یک عبارت می شود. به عنوان مثال، مجموع دو عبارت نیز یک عبارت است.
- درخت تجزیه را می توان برای تشکیل یک درخت نحو فشرده کرد.
- در صورتی که ورودی مطابق با دستور زبان نباشد، خطای نحوی در این سطح قابل تشخیص است.
حال تمامی این هارا گفتیم که به این نتیجه برسیم Semantic Analyzer درخت تجزیه را تأیید می کند
که آیا معنی دار است یا نه. علاوه بر این یک درخت تجزیه تایید شده تولید می کند.
همچنین بررسی نوع، بررسی برچسب و بررسی کنترل جریان را انجام می دهد.
3-Semantic Analyzer
Semantic Analyzer معنای ایستا هر ساختار را بررسی می کند.
4-Intermediate Code Generator
Lexical Analyzer برنامه را به “توکن ها” تقسیم می کند، Syntax Analyzer “جملات” را در برنامه
با استفاده از syntax زبان تشخیص می دهد و Semantic Analyzer معنای ایستا هر ساختار را بررسی می کند.
در نهایت Intermediate Code Generator کد را تولید می کند.
طراحی کامپایلر
ما اساساً دو فاز کامپایلر داریم، فاز تحلیل و فاز سنتز.
مرحله تجزیه و تحلیل یک نمایش میانی از کد منبع داده شده ایجاد می کند.
مرحله سنتز یک برنامه هدف معادل از نمایش میانی ایجاد می کند.
- جدول نمایه ها (Symbol Table) :
یک ساختار داده ای است که توسط کامپایلر استفاده و نگهداری می شود و شامل نام تمام شناسه ها به همراه انواع آنها است.
با یافتن سریع شناسه ها به کامپایلر کمک می کند تا به راحتی کار کند.
تجزیه و تحلیل یک برنامه منبع عمدتاً به سه مرحله تقسیم می شود که عبارتند از :
- تحلیل خطی :
این شامل یک مرحله اسکن است که در آن جریان کاراکترها از چپ به راست خوانده می شود.
سپس به نشانه های مختلف با معنای جمعی گروه بندی می شود.
- تحلیل سلسله مراتبی :
در این مرحله تجزیه و تحلیل، بر اساس معنای جمعی، نشانه ها به صورت سلسله مراتبی در گروه های تودرتو طبقه بندی می شوند.
- تحلیل معنایی :
این مرحله برای بررسی اینکه آیا اجزای برنامه منبع معنادار هستند یا نه استفاده می شود.
کامپایلر دارای دو ماژول به نام های front و back است.
Front-end شامل Lexical analyzer، semantic analyzer، syntax analyzer و intermediate code generator است و بقیه برای تشکیل انتهای پشتی مونتاژ می شوند.
Symbol Table (جدول نمادها) در کامپایلر
Symbol Table یک ساختار داده مهم است که توسط کامپایلر به منظور پیگیری معنایی متغیرها ایجاد و نگهداری می شود،
یعنی اطلاعات مربوط به دامنه و اطلاعات الزام آور در مورد نام ها، اطلاعات مربوط به نمونه هایی از موجودیت های مختلف مانند نام متغیرها و توابع، کلاس ها را ذخیره می کند ؛ مانند اشیاء و ..
اطلاعات توسط مراحل تجزیه و تحلیل کامپایلر جمع آوری می شود و توسط مراحل سنتز کامپایلر برای تولید کد استفاده می شود.
توسط کامپایلر برای دستیابی به کارایی زمان کامپایل استفاده می شود.
توسط فازهای مختلف کامپایلر به شرح زیر استفاده می شود :
- Lexical Analysis (تجزیه و تحلیل لغوی) : ورودی های جدید را در جدول ایجاد می کند، به عنوان مثال مانند ورودی های مربوط به نشانه ها.
- Syntax Analysis (تجزیه و تحلیل نحوی) : اطلاعات مربوط به نوع ویژگی، محدوده، بعد، خط مرجع، کاربری و … را در جدول اضافه می کند.
- Semantic Analysis (تحلیل معنایی) : از اطلاعات موجود در جدول برای بررسی معنایی استفاده میکند، یعنی تأیید میکند که عبارات و تخصیصها از نظر معنایی درست هستند (بررسی نوع) و بر اساس آن به روز میشوند.
- Intermediate Code generation (تولید کد میانی) : به جدول نمادی برای دانستن اینکه چه مقدار و چه نوع زمان اجرا اختصاص داده شده است اشاره می کند و جدول به اضافه کردن اطلاعات متغیر موقت کمک می کند.
- Code Optimization (بهینه سازی کد) : از اطلاعات موجود در جدول نمادها برای بهینه سازی وابسته به ماشین استفاده می کند.
- Target Code generation (تولید کد هدف) : با استفاده از اطلاعات آدرس شناسه موجود در جدول، کد تولید می کند.
موارد ذخیره شده در جدول نمادها عبارتند از :
- نام متغیرها و ثابت ها
- نام Procedure و توابع
- ثابت های حرفی و رشته ها
- برچسب ها در سورس
پیاده سازی جدول نمادها
در زیر ساختارهای داده رایج برای پیاده سازی جدول نمادها استفاده می شود:
1- list
در این روش از یک آرایه برای ذخیره اسامی و اطلاعات مرتبط استفاده می شود.
یک اشاره گر “در دسترس” در پایان تمام رکوردهای ذخیره شده نگهداری می شود و نام های جدید به ترتیب به محض رسیدن اضافه می شوند.
برای جستجوی نام از ابتدای لیست شروع می کنیم تا اشاره گر موجود باشد و اگر پیدا نشد با خطای “استفاده از نام اعلام نشده” مواجه می شویم.
هنگام درج یک نام جدید، باید اطمینان حاصل کنیم که از قبل وجود نداشته باشد، در غیر این صورت خطایی رخ می دهد، به عنوان مثال “چند نام تعریف شده”
هزینه ی بهینه O1 است، اما جستجو و هزینه برای جداول بزرگ کند است ، به طور متوسط O(n).
مزیت آن این است که حداقل فضا را اشغال می کند.
2- linked list ( لیست پیوندی)
این پیاده سازی از یک لیست پیوندی استفاده می کند. یک فیلد پیوند به هر رکورد اضافه می شود.
جستجوی نام ها به ترتیب نشان داده شده توسط فیلد پیوند انجام می شود.
یک اشاره گر First برای اشاره به اولین رکورد جدول نمادها نگهداری می شود.
هزینه O1 است، اما جستجو و هزینه برای جداول بزرگ کند است ، به طور متوسط O(n).
3- Hash Table (جدول هش )
در طرح هش، دو جدول نگهداری می شود – جدول هش و جدول نمادها و متداول ترین روش مورد استفاده برای پیاده سازی جداول نماد هستند.
جدول هش آرایه ای است با محدوده شاخص : 0 تا اندازه جدول – 1.
این ورودی ها اشاره گرهایی هستند که به نام جدول نمادها اشاره می کنند.
برای جستجوی نام از یک تابع هش استفاده می کنیم که به عدد صحیحی بین 0 تا اندازه جدول – 1 منجر می شود.
درج و جستجو می تواند بسیار سریع انجام شود O1
مزیت آن جستجوی سریع و هزینه ی کم است اما عیب آن این است که اجرای هش پیچیده است.
4- Binary Search Tree (درخت جستجوی باینری)
روش دیگر برای پیادهسازی جدول نمادها استفاده از درخت جستجوی دودویی است، یعنی دو فیلد پیوند فرزند چپ و راست اضافه میکنیم.
همه نام ها به عنوان فرزند گره ریشه ایجاد می شوند که همیشه از ویژگی درخت جستجوی باینری پیروی می کند.
درج و جستجو به طور متوسط O(log2 n) است.
مدیریت ارورها در کامپایلر
در کامپایلرها فرایندی برای خطاهای وجود دارد تحت عنوان Error Handling که این فرایند وظیفه
شناسایی هر خطا، گزارش آن به کاربر و سپس ایجاد یک استراتژی بازیابی
و اجرای آنها برای رسیدگی به خطا است. در طول کل این فرآیند، زمان پردازش برنامه نباید کند باشد.
همانطور که گفته شد این سه عملیات وظیفه ی اصلی آن است :
- تشخیص خطا
- گزارش خطا
- بازیابی خطا
خطاهای برنامه باید توسط تجزیه کننده شناسایی و گزارش شود. هر زمان که خطایی رخ می دهد،
parser ( تجزیه کننده ) می تواند آن را مدیریت کرده و به تجزیه بقیه ورودی ادامه دهد.
اگرچه تجزیه کننده عمدتاً مسئول بررسی خطاها است، اما ممکن است در مراحل مختلف فرآیند کامپایل خطا رخ دهد.
بنابراین، خطاها انواع مختلفی دارند که برخی از آنها عبارتند از:
- خطای منطقی
- خطاهای زمان اجرا
- خطای زمان کامپایل
انواع خطاها
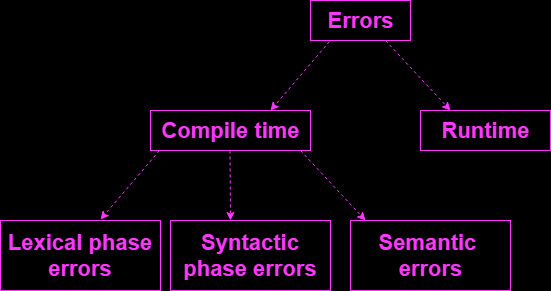
خطای منطقی :
زمانی اتفاق میافتد که برنامهها به درستی کار نمیکنند .
خروجی های غیرمنتظره یا ناخواسته یا سایر رفتارها ممکن است از یک خطای منطقی ناشی شود.
خطاهای زمان اجرا :
همانطور که ازنام آن مشخص است خطایی است که در حین اجرای یک برنامه رخ می دهد و
معمولاً به دلیل پارامترهای ناهماهنگ سیستم یا داده های ورودی نادرست رخ می دهد.
نبود حافظه کافی برای اجرای برنامه یا تداخل حافظه با برنامه دیگر و خطای منطقی نمونه ای از این موارد است.
خطاهای منطقی زمانی رخ می دهد که کد اجرا شده نتیجه مورد انتظار را ایجاد نمی کند.
خطاهای منطقی به بهترین وجه با اشکال زدایی دقیق برنامه کنترل می شوند.
خطای زمان کامپایل :
این خطا در زمان کامپایل، قبل از اجرای برنامه رخ می دهد .
عدم وجود مرجع فایل که مانع از کامپایل موفقیت آمیز برنامه می شود نمونه ای از دلایل رخ دادن این خطا است .
راه های بازیابی و تشخیص خطاها

بازیابی حالت Panic
این سادهترین راه برای بازیابی خطا است و همچنین از ایجاد حلقههای بینهایت توسط تجزیهگر در حین بازیابی خطا جلوگیری میکند.
تجزیهکننده نماد ورودی را یکی یکی کنار میگذارد تا زمانی که یکی از مجموعههای مشخص شده (مانند پایان، نقطه ویرگول) از نشانههای همگامسازی (معمولاً پایاندهنده عبارت هستند) پیدا شود.
این زمانی کافی است که وجود چندین خطا در یک عبارت نادر باشد.
مثال: عبارت اشتباه (1 + + 2) + 3 را در نظر بگیرید.
بازیابی حالت Panic: به عدد صحیح بعدی بروید و سپس ادامه دهید.
Bison : از خطای ترمینال ویژه برای توصیف مقدار ورودی برای رد شدن استفاده کنید.
بازیابی حالت Phase
هنگامی که یک خطا کشف می شود، تجزیه کننده تصحیح محلی را در ورودی باقی مانده انجام می دهد.
اگر تجزیه کننده با خطا مواجه شود، اصلاحات لازم را در ورودی باقیمانده انجام می دهد تا تجزیه کننده بتواند به تجزیه بقیه عبارت ادامه دهد.
می توانید با حذف نیم ویرگول های اضافی، جایگزینی ویرگول با نقطه ویرگول، یا معرفی مجدد نقطه ویرگول های از دست رفته، خطا را تصحیح کنید.
برای جلوگیری از قرار گرفتن در یک حلقه بی نهایت در طول اصلاح، باید نهایت دقت را انجام داد.
هرگاه پیشوندی در ورودی باقیمانده یافت شود، با رشته ای جایگزین می شود. به این ترتیب تجزیه کننده می تواند به اجرای خود ادامه دهد.

مهرسا امینی
برنامه نویس ، انیماتور ، سئوکار
در زندگی رویاهات را دنبال کن



